The typical “successful” venture portfolio is often described as having the following outcome:
- 1/3 of companies fail
- 1/3 of companies return capital (or make a small amount of money)
- 1/3 of companies do well
Fred Wilson, for example, described this a few years ago:
I’ve said many times on this blog that our target batting average is “1/3, 1/3, 1/3” which means that we expect to lose our entire investment on 1/3 of our investments, we expect to get our money back (or maybe make a small return) on 1/3 of our investments, and we expect to generate the bulk of our returns on 1/3 of our investments.
It’s a generalization but one that’s pretty well accepted in venture circles and it’s how many VCs describe target fund distribution, myself included. But does this heuristic match reality?
Actually no.
Correlation Ventures just released a study that shows the distribution of outcomes across over 21,000 financings and spanning the years 20014-2013. For those of you that don’t know Correlation, they take a data driven approach to co-investing – essentially creating an algorithm that predicts the success of a company based on a number of factors that include both business trajectory as well as financing trajectory (we’re co-investors with Correlation in Distil, for example). The result is that they process a lot of data. Which leads to some pretty interested insights.
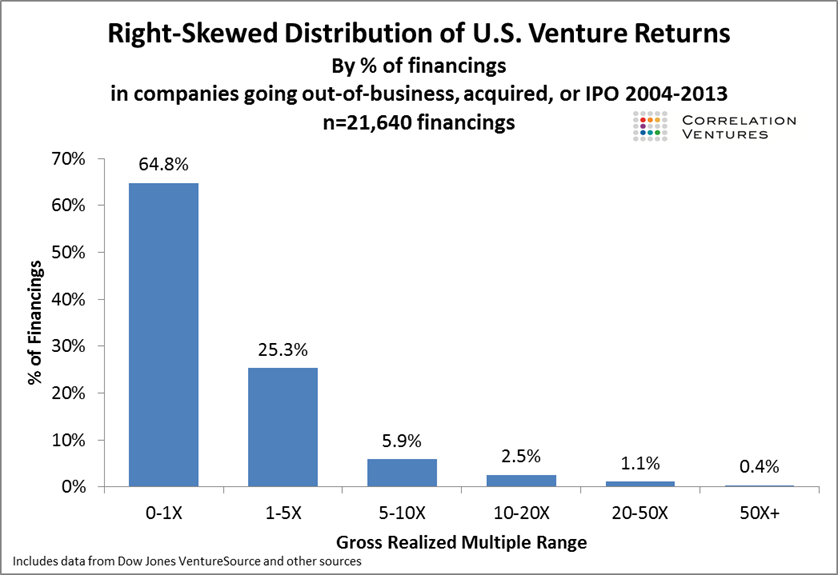
Based on their data, a full 65% of financings fail to return 1x capital. And perhaps more interestingly, only 4% produce a return of 10x or more and only 10% produce a return of 5x or more. These data suggest that the heuristic I site above potentially presents a rosier picture of the venture industry than reality suggests is the case (there are some missing data here in that the vast majority of companies are in the 0-1x category but the data within that category weren’t released – but my suspicion is that within that category the distribution of outcomes follows a similar power curve).
This really underscores the challenge of creating a venture portfolio that produces reasonable returns. If you were to actually construct a portfolio based on these averages, a $100M venture fund investing in 20 companies would produce a gross return of approximately $206M (that’s before fees and expenses). The resulting fund would have an IRR in the range of 10% (the exact IRR would depend on the timing of the cash flows, but I constructed a few models to approximate this and 10% was the average return). That’s hardly something to write home about and underscores the challenge of being “average” in this industry.
Hidden in this exercise – and perhaps more important – is the challenge of finding companies at the right side of the distribution chart. In my hypothetical $100M fund with 20 investments, the total number of financings producing a return above 5x was 0.8 – producing almost $100M of proceeds. My theoretical fund actually didn’t find their purple unicorn, they found 4/5ths of that company. If they had missed it, they would have failed to return capital after fees. Even if we doubled the number of portfolio companies in the hypothetical portfolio, a full quarter of the fund’s return comes from the roughly ½ of a company they invested in that generated 10x or above. Had they missed it, they would have produced a return that roughly approximated investing in bonds – not the kind of risk adjusted return they or their investors were looking for.
It’s important to note here that I’m extrapolating a bit – the Correlation data are based on financings, not companies (I asked – they didn’t have a sort at an entity level in this exercise). I thought about ways to normalize this but came to the conclusion that the best normalization was to use the raw data and caveat that it was financing level, not company level. I’m going to work with Correlation to get entity level detail the next time the do this exercise.
All of this math simply underscores how important winners are to venture returns and how difficult it is to find them.
Note: An obvious, but important, thank you to Correlation for allowing me to share these data as they were originally prepared as a private exercise for Correlation and their venture partners. As I mention above, we’re coinvestors with Correlation in Distil Networks. They have a bit of a unique model for co-investing which allows them to see a lot of data on a lot of companies to support their data driven investment thesis (which also allows them to reach fast investment decisions).